 Статьи
Hardware
Видеокарты
Статьи
Hardware
Видеокарты
CUDA мы катимся: технология NVIDIA CUDA

Согласно Дарвинской теории эволюции, первая человекообразная обезьяна (если быть точным – homo antecessor, человек-предшественник) превратилась впоследствии в нас. Многотонные вычислительные центры с тысячью и больше радиоламп, занимающие целые комнаты, сменились полукилограммовыми ноутами, которые, кстати, не уступят в производительности первым. Допотопные печатные машинки превратились в печатающие что угодно и на чем угодно (даже на теле человека) многофункциональные устройства. Процессорные гиганты вдруг вздумали замуровать графическое ядро в «камень». А видеокарты стали не только показывать картинку с приемлемым FPS и качеством графики, но и производить всевозможные вычисления. Да еще как производить! О технологии многопоточных вычислений средствами GPU, NVIDIA CUDA и пойдет речь.
![]()
Почему GPU?
Интересно, почему всю вычислительную мощь решили переложить на графический адаптер? Как видно, процессоры еще в моде, да и вряд ли уступят свое теплое местечко. Но у GPU есть пара козырей в рукаве вместе с джокером, да и рукавов хватает. Современный центральный процессор заточен под получение максимальной производительности при обработке целочисленных данных и данных с плавающей запятой, особо не заботясь при этом о параллельной обработке информации. В то же время архитектура видеокарты позволяет быстро и без проблем «распараллелить» обработку данных. С одной стороны, идет обсчет полигонов (за счет 3D-конвейера), с другой – пиксельная обработка текстур. Видно, что происходит «слаженная разбивка» нагрузки в ядре карты. Кроме того, работа памяти и видеопроцессора оптимальнее, чем связка «ОЗУ-кэш-процессор». В тот момент, когда единица данных в видеокарте начинает обрабатываться одним потоковым процессором GPU, другая единица параллельно загружается в другой, и, в принципе, легко можно достичь загруженности графического процессора, сравнимой с пропускной способностью шины, однако для этого загрузка конвейеров должна осуществляться единообразно, без всяких условных переходов и ветвлений. Центральный же процессор в силу своей универсальности требует для своих процессорных нужд кэш, заполненный информацией.
Ученые мужи задумались насчет работы GPU в параллельных вычислениях и математике и вывели теорию, что многие научные расчеты во многом схожи с обработкой 3D-графики. Многие эксперты считают, что основополагающим фактором в развитии GPGPU (General Purpose computation on GPU – универсальные расчеты средствами видеокарты) стало появление в 2003 году проекта Brook GPU.
Создателям проекта из Стэндфордского университета предстояло решить непростую проблему: аппаратно и программно заставить графический адаптер производить разноплановые вычисления. И у них это получилось. Используя универсальный язык C, американские ученые заставили работать GPU как процессор, с поправкой на параллельную обработку. После Brook появился целый ряд проектов по VGA-расчетам, таких как библиотека Accelerator, библиотека Brahma, система метапрограммирования GPU++ и другие.
CUDA!
Предчувствие перспективности разработки заставило AMD и NVIDIA вцепиться в Brook GPU, как питбуль. Если опустить маркетинговую политику, то, реализовав все правильно, можно закрепиться не только в графическом секторе рынка, но и в вычислительном (посмотри на специальные вычислительные карты и серверы Tesla с сотнями мультипроцессоров), потеснив привычные всем CPU.
Естественно, «повелители FPS» разошлись у камня преткновения каждый по своей тропе, но основной принцип остался неизменным – производить вычисления средствами GPU. И сейчас мы подробнее рассмотрим технологию «зеленых» – CUDA (Compute Unified Device Architecture).
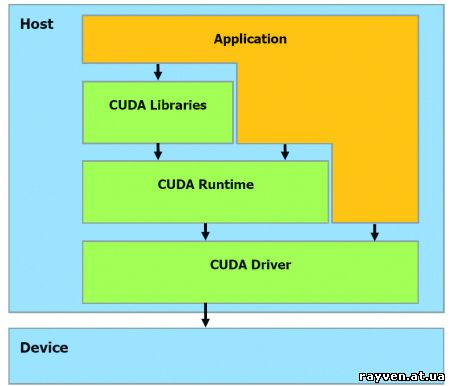
Работа нашей «героини» заключается в обеспечении API, причем сразу двух. Первый – высокоуровневый, CUDA Runtime, представляет собой функции, которые разбиваются на более простые уровни и передаются нижнему API – CUDA Driver. Так что фраза «высокоуровневый» применима к процессу с натяжкой. Вся соль находится именно в драйвере, и добыть ее помогут библиотеки, любезно созданные разработчиками NVIDIA: CUBLAS (средства для математических расчетов) и FFT (расчет посредством алгоритма Фурье). Ну что ж, перейдем к практической части материала.
Терминология CUDA
NVIDIA оперирует весьма своеобразными определениями для CUDA API. Они отличаются от определений, применяемых для работы с центральным процессором.
Поток (thread) – набор данных, который необходимо обработать (не требует больших ресурсов при обработке).
Варп (warp) – группа из 32 потоков. Данные обрабатываются только варпами, следовательно варп – это минимальный объем данных.
Блок (block) – совокупность потоков (от 64 до 512) или совокупность варпов (от 2 до 16).
Сетка (grid) – это совокупность блоков. Такое разделение данных применяется исключительно для повышения производительности. Так, если число мультипроцессоров велико, то блоки будут выполняться параллельно. Если же с картой не повезло (разработчики рекомендуют для сложных расчетов использовать адаптер не ниже уровня GeForce 8800 GTS 320 Мб), то блоки данных обработаются последовательно.
Также NVIDIA вводит такие понятия, как ядро (kernel), хост (host) и девайс (device).
Работаем!
Для полноценной работы с CUDA нужно:
1. Знать строение шейдерных ядер GPU, так как суть программирования заключается в равномерном распределении нагрузки между ними.
2. Уметь программировать в среде C, с учетом некоторых аспектов.
Разработчики NVIDIA раскрыли «внутренности» видеокарты несколько иначе, чем мы привыкли видеть. Так что волей-неволей придется изучать все тонкости архитектуры. Разберем строение «камня» G80 легендарной GeForce 8800 GTX.
Шейдерное ядро состоит из восьми TPC (Texture Processor Cluster) – кластеров текстурных процессоров (так, у GeForce GTX 280 – 15 ядер, у 8800 GTS их шесть, у 8600 – четыре и т.д.). Те, в свою очередь, состоят из двух потоковых мультипроцессоров (streaming multiprocessor – далее SM). SM (их всего 16) состоит из front end (решает задачи чтения и декодирования инструкций) и back end (конечный вывод инструкций) конвейеров, а также восьми scalar SP (shader processor) и двумя SFU (суперфункциональные блоки). За каждый такт (единицу времени) front end выбирает варп и обрабатывает его. Чтобы все потоки варпа (напомню, их 32 штуки) обработались, требуется 32/8 = 4 такта в конце конвейера.

Каждый мультипроцессор обладает так называемой общей памятью (shared memory). Ее размер составляет 16 килобайт и предоставляет программисту полную свободу действий. Распределяй как хочешь :). Shared memory обеспечивает связь потоков в одном блоке и не предназначена для работы с пиксельными шейдерами.
Также SM могут обращаться к GDDR. Для этого им «пришили» по 8 килобайт кэш-памяти, хранящих все самое главное для работы (например, вычислительные константы).
Мультипроцессор имеет 8192 регистра. Число активных блоков не может быть больше восьми, а число варпов – не больше 768/32 = 24. Из этого видно, что G80 может обработать максимум 32*16*24 = 12288 потоков за единицу времени. Нельзя не учитывать эти цифры при оптимизации программы в дальнейшем (на одной чашу весов – размер блока, на другой – количество потоков). Баланс параметров может сыграть важную роль в дальнейшем, поэтому NVIDIA рекомендует использовать блоки со 128 или 256 потоками. Блок из 512 потоков неэффективен, так как обладает повышенными задержками. Учитывая все тонкости строения GPU видеокарты плюс неплохие навыки в программировании, можно создать весьма производительное средство для параллельных вычислений. Кстати, о программировании...
Программирование
Для «творчества» вместе с CUDA требуется видеокарта GeForce не ниже восьмой серии. С официального сайта нужно скачать три программных пакета: драйвер с поддержкой CUDA (для каждой ОС – свой), непосредственно пакет CUDA SDK (вторая бета-версия) и дополнительные библиотеки (CUDA toolkit). Технология поддерживает операционные системы Windows (XP и Vista), Linux и Mac OS X. Для изучения я выбрал Vista Ultimate Edition x64 (забегая вперед, скажу, что система вела себя просто превосходно). В момент написания этих строк актуальным для работы был драйвер ForceWare 177.35. В качестве набора инструментов использовался программный пакет Borland C++ 6 Builder (хотя подойдет любая среда, работающая с языком C).
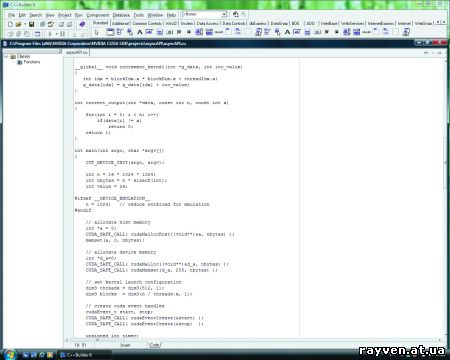
Человеку, знающему язык, будет легко освоиться в новой среде. Требуется лишь запомнить основные параметры. Ключевое слово _global_ (ставится перед функцией) показывает, что функция относится к kernel (ядру). Ее будет вызывать центральный процессор, а вся работа произойдет на GPU. Вызов _global_ требует более конкретных деталей, а именно размер сетки, размер блока и какое ядро будет применено. Например, строчка _global_ void saxpy_parallel<<<X,Y>>>, где X – размер сетки, а Y – размер блока, задает эти параметры.
Символ _device_ означает, что функцию вызовет графическое ядро, оно же выполнит все инструкции. Эта функция располагается в памяти мультипроцессора, следовательно, получить ее адрес невозможно. Префикс _host_ означает, что вызов и обработка пройдут только при участии CPU. Надо учитывать, что _global_ и _device_ не могут вызывать друг друга и не могут вызывать самих себя.
Также язык для CUDA имеет ряд функций для работы с видеопамятью: cudafree (освобождение памяти между GDDR и RAM), cudamemcpy и cudamemcpy2D (копирование памяти между GDDR и RAM) и cudamalloc (выделение памяти).
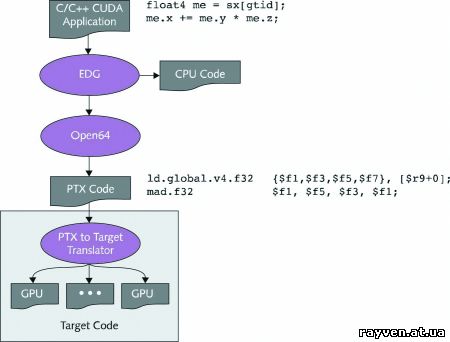
Все программные коды проходят компиляцию со стороны CUDA API. Сначала берется код, предназначенный исключительно для центрального процессора, и подвергается стандартной компиляции, а другой код, предназначенный для графического адаптера, переписывается в промежуточный язык PTX (сильно напоминает ассемблер) для выявления возможных ошибок. После всех этих «плясок» происходит окончательный перевод (трансляция) команд в понятный для GPU/CPU язык.
Набор для изучения
Практически все аспекты программирования описаны в документации, идущей вместе с драйвером и двумя приложениями, а также на сайте разработчиков. Размера статьи не хватит, чтобы описать их (заинтересованный читатель должен приложить малую толику стараний и изучить материал самостоятельно).
Специально для новичков разработан CUDA SDK Browser. Любой желающий может ощутить силу параллельных вычислений на своей шкуре (лучшая проверка на стабильность – работа примеров без артефактов и вылетов). Приложение имеет большой ряд показательных мини-программок (61 «тест»). К каждому опыту имеется подробная документация программного кода плюс PDF-файлы. Сразу видно, что люди, присутствующие со своими творениями в браузере, занимаются серьезной работой. Тут же можно сравнить скорости работы процессора и видеокарты при обработке данных. Например, сканирование многомерных массивов видеокартой GeForce 8800 GT 512 Мб с блоком с 256 потоками производит за 0.17109 миллисекунды. Технология не распознает SLI-тандемы, так что если у тебя дуэт или трио, отключай функцию «спаривания» перед работой, иначе CUDA увидит только один девайс. Двуядерный AMD Athlon 64 X2 (частота ядра 3000 МГц) тот же опыт проходит за 2.761528 миллисекунды. Получается, что G92 более чем в 16 раз быстрее «камня» AMD! Как видишь, далеко не экстремальная система в тандеме с нелюбимой в массах операционной системой показывает неплохие результаты.

Помимо браузера существует ряд полезных обществу программ. Adobe адаптировала свои продукты к новой технологии. Теперь Photoshop CS4 в полной мере использует ресурсы графических адаптеров (необходимо скачать специальный плагин). Такими программами, как Badaboom media converter и RapiHD можно произвести декодирование видео в формат MPEG-2. Для обработки звука неплохо подойдет бесплатная утилита Accelero. Количество софта, заточенного под CUDA API, несомненно, будет расти.
А это время…
А пока ты читаешь сей материал, трудяги из процессорных концернов разрабатывают свои технологии по внедрению GPU в CPU. Со стороны AMD все понятно: у них есть большущий опыт, приобретенный вместе с ATI.
Творение «микродевайсеров», Fusion, будет состоять из нескольких ядер под кодовым названием Bulldozer и видеочипа RV710 (Kong). Их взаимосвязь будет осуществляться за счет улучшенной шины HyperTransport. В зависимости от количества ядер и их частотных характеристик AMD планирует создать целую ценовую иерархию «камней». Также планируется производить процессоры как для ноутбуков (Falcon), так и для мультимедийных гаджетов (Bobcat). Причем именно применение технологии в портативных устройствах будет первоначальной задачей для канадцев. С развитием параллельных вычислений применение таких «камней» должно быть весьма популярно.
Intel немножко отстает по времени со своей Larrabee. Продукты AMD, если ничего не случится, появятся на прилавках магазинов в конце 2009 – начале 2010 года. А решение противника выйдет на свет божий только почти через два года.
Larrabee будет насчитывать большое количество (читай – сотни) ядер. Вначале же выйдут продукты, рассчитанные на 8 – 64 ядера. Они очень сходны с Pentium, но довольно сильно переработаны. Каждое ядро имеет 256 килобайт кэша второго уровня (со временем его размер увеличится). Взаимосвязь будет осуществляться за счет 1024-битной двунаправленной кольцевой шины. Интел говорит, что их «дитя» будет отлично работать с DirectX и Open GL API (для «яблочников»), поэтому никаких программных вмешательств не потребуется.
А к чему я все это тебе поведал? Очевидно, что Larrabee и Fusion не вытеснят обычные, стационарные процессоры с рынка, так же, как не вытеснят с рынка видеокарты. Для геймеров и экстремалов пределом мечтаний по-прежнему останется многоядерный CPU и тандем из нескольких топовых VGA. Но то, что даже процессорные компании переходят на параллельные вычисления по принципам, аналогичным GPGPU, говорит уже о многом. В частности о том, что такая технология, как CUDA, имеет право на существование и, по всей видимости, будет весьма популярна.
Небольшое резюме
Параллельные вычисления средствами видеокарты – всего лишь хороший инструмент в руках трудолюбивого программиста. Вряд ли процессорам во главе с законом Мура придет конец. Компании NVIDIA предстоит пройти еще длинный путь по продвижению в массы своего API (то же можно сказать и о детище ATI/AMD). Какой он будет, покажет будущее. Так что CUDA will be back :).
P.S. Начинающим программистам и заинтересовавшимся людям рекомендую посетить следующие «виртуальные заведения»: официальный сайт NVIDIA и сайт GPGPU.com. Вся предоставленная информация – на английском языке, но, спасибо хотя бы, что не на китайском. Так что дерзай! Надеюсь, что автор хоть немного помог тебе в захватывающих начинаниях познания CUDA!
Источник
 обсудить на форуме
обсудить на форуме |
1719 визитов ↳ 0 ответов | Ваше мнение о материале | Голосовало: 1 |





