Статьи
iT заметки
Программирование
Статьи
iT заметки
Программирование
Введение в GPU-вычисления – CUDA/OpenCL
Введение в GPU-вычисления
Видеокарты – это не только показатель фпс в новейших играх, это еще и первобытная мощь параллельных вычислений, оставляющая позади самые могучие процессоры. В видеокартах таится множество простых процессоров, умеющих лихо перемалывать большие объемы данных. GPU-программирование – это та отрасль параллельных вычислений где все еще никак не устаканятся единые стандарты – что затрудняет использование простаивающих мощностей.
В этой заметке собрана информация которая поможет понять общие принципы GPU-программирования.
Введение в архитектуру GPU
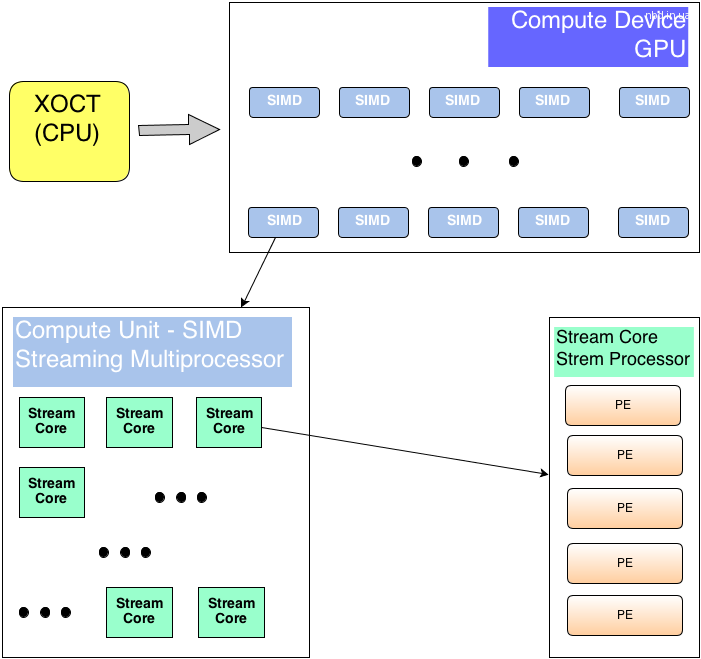
Разделяют два вида устройств – то которое управляет общей логикой – host, и то которое умеет быстро выполнить некоторый набор инструкций над большим объемом данных – device.

В роли хоста обычно выступает центральный процессор (CPU – например i5/i7).
В роли вычислительного устройства – видеокарта (GPU – GTX690/HD7970). Видеокарта содержит Compute Units – процессорные ядра. Неразбериху вводят и производители NVidiaназывает свои Streaming Multiprocessor unit или SMX , а
ATI – SIMD Engine или Vector Processor. В современных игровых видеокартах – их 8-32.
Процессорные ядра могут исполнять несколько потоков за счет того, что в каждом содержится несколько (8-16)потоковых процессоров (Stream Cores или Stream Processor). Для карт NVidia – вычисления производятся непосредственно на потоковых процессорах, но ATI ввели еще один уровень абстракции – каждый потоковый процессор, состоит изprocessing elements – PE (иногда называемых ALU – arithmetic and logic unit) – и вычисления происходят на них.
Необходимо явно подчеркнуть что конкретная архитектура (число всяческих процессоров) и вычислительные возможности варьируются от модели к модели – что несколько влияет на универсальность и простоту кода для видеокарт от обоих производителей.
Для CUDA-устройств от NVidia это sm10, sm20, sm30 и т.д. Для OpenCL видеокарт от ATI/NVidia определяющее значение имеет версия OpenCL реализованная в драйверах от производителя 1.0, 1.1, 1.2 и поддержка особенностей на уровне железа. Да, вы вполне можете столкнуться с ситуацией когда на уровне железа какие-то функции просто не реализованы (как например локальная память на амд-ешных видеокарт линейки HD4800). Да, вы вполне можете столкнуться с ситуацией когда какие-то функции не реализованы в драйверах (на момент написания – выполнение нескольких ядер на видео-картах от NVidia с помощью OpenCL).
Программирование для GPU

Программы пишутся на расширении языка Си от NVidia/OpenCL и компилируются с помощью специальных компиляторов входящих в SDK. У каждого производителя разумеется свой. Есть два варианта сборки – под целевую платформу – когда явно указывается на каком железе будет исполнятся код или в некоторый промежуточный код, который при запуске на целевом железе будет преобразован драйвером в набор конкретных инструкций для используемой архитектуры (с поправкой на вычислительные возможности железа).
 Выполняемая на GPU программа называется ядром – kernel– что для CUDA что для OpenCL это и будет тот набор инструкций которые применяются ко всем данным. Функция одна, а данные на которых она выполняется – разные – принцип SIMD.
Выполняемая на GPU программа называется ядром – kernel– что для CUDA что для OpenCL это и будет тот набор инструкций которые применяются ко всем данным. Функция одна, а данные на которых она выполняется – разные – принцип SIMD.
Важно понимать что память хоста (оперативная) и видеокарты – это две разные вещи и перед выполнением ядра на видеокарте, данные необходимо загрузить из оперативной памяти хоста в память видеокарты. Для того чтобы получить результат – необходимо выполнить обратный процесс. Здесь есть ограничения по скорости PCI-шины – потому чем реже данные будут гулять между видеокартой и хостом – тем лучше.
Драйвер CUDA/OpenCL разбивает входные данные на множество частей (потоки выполнения объединенные в блоки) и назначает для выполнения на каждый потоковый процессор. Программист может и должен указывать драйверу как максимально эффективно задействовать существующие вычислительные ресурсы, задавая размеры блоков и число потоков в них. Разумеется, максимально допустимые значения варьируются от устройства к устройству. Хорошая практика – перед выполнением запросить параметры железа, на котором будет выполняться ядро и на их основании вычислить оптимальные размеры блоков.
Схематично, распределение задач на GPU происходит так:

Выполнение программы на GPU
work-item (OpenCL) или thread (CUDA) – ядро и набор данных, выполняется на Stream Processor (Processing Element в случае ATI устройств).
work group (OpenCL) или thread block (CUDA) выполняется на Multi Processor (SIMD Engine)
Grid (набор блоков такое понятие есть только у НВидиа) = выполняется на целом устройстве – GPU. Для выполнения на GPU все потоки объединяются в варпы (warp – CUDA) или вейффронты (wavefront – OpenCL) – пул потоков, назначенных на выполнение на одном отдельном мультипроцессоре. То есть если число блоков или рабочих групп оказалось больше чем число мултипроцессоров – фактически, в каждый момент времени выполняется группа (или группы) объединенные в варп – все остальные ожидают своей очереди.
Одно ядро может выполняться на нескольких GPU устройствах (как для CUDA так и для OpenCL, как для карточек ATI так и для NVidia).
Одно GPU-устройство может одновременно выполнять несколько ядер (как для CUDA так и для OpenCL, для NVidia – начиная с архитектуры 20 и выше). Ссылки по данным вопросам см. в конце статьи.
Модель памяти OpenCL (в скобках – терминология CUDA)

Здесь главное запомнить про время доступа к каждому виду памяти. Самый медленный это глобальная память – у современных видекарт ее аж до 6 Гб. Далее по скорости идет разделяемая память (shared – CUDA, local – OpenCL) – общая для всех потоков в блоке (thread block – CUDA, work-group – OpenCL) – однако ее всегда мало – 32-48 Кб для мультипроцессора. Самой быстрой является локальная память за счет использования регистров и кеширования, но надо понимать что все что не уместилось в кеши\регистры – будет хранится в глобальной памяти со всеми вытекающими.
Паттерны параллельного программирования для GPU
1. Map

Map – GPU parallel pattern
Тут все просто – берем входной массив данных и к каждому элементу применяем некий оператор – ядро – никак не затрагивающий остальные элементы – т.е. читаем и пишем в определенные ячейки памяти.
Отношение – как один к одному (one-to-one).
out[i]=operator(int[i])
пример – перемножение матриц, оператор инкремента или декремента примененный к каждому элементу матрицы и т.п.
2. Scatter

Scatter – GPU parallel pattern
Для каждого элемента входного массива мы вычисляем позицию в выходном массиве, на которое он окажет влияние (путем применения соответствующего оператора).
out[Loc[i]] = operator(in[i])
Отношение – как один ко многим (one-to-many).
3. Transpose

Transpose – GPU parallel pattern
Данный паттерн можно рассматривать как частный случай паттерна scatter.
Используется для оптимизации вычислений – перераспределяя элементы в памяти можно достичь значительного повышения производительности.
4. Gather

Gather – GPU parallel pattern
Является обратным к паттерну Scatter – для каждого элемента в выходном массиве мы вычисляем индексы элементов из входного массива, которые окажут на него влияние:
out[i] = operator(in[Loc[i]])
Отношение – несколько к одному (many-to-one).
5. Stencil

Stencil – GPU parallel pattern
Данный паттерн можно рассматривать как частный случай паттерна gather. Здесь для получения значения в каждой ячейке выходного массива используется определенный шаблон для вычисления всех элементов входного массива, которые повлияют на финальное значение. Всевозможные фильтры построены именно по этому принципу.
Отношение несколько к одному (several-to-one)
Пример: фильтр Гауссиана.
6. Reduce

Reduce – GPU parallel pattern
Отношение все к одному (All-to-one)
Пример – вычисление суммы или максимума в массиве.
7. Scan/ Sort
При вычислении значения в каждой ячейке выходного массива необходимо учитывать значения каждого элемента входного. Существует две основные реализации – Hillis and Steele и Blelloch.
out[i] = F[i] = operator(F[i-1],in[i])
Отношение все ко всем (all-to-all).
Примеры – сортировка данных.
Полезные ссылки
Архитектура GPU – http://www.ixbt.com/video3/rad.shtml
Введение в CUDA:
http://cgm.computergraphics.ru/issues/issue16/cuda
Введение в OpenCL:
http://www.drdobbs.com/parallel/a-gentle-introduction-to-opencl/231002854
http://opencl.codeplex.com/wikipage?title=OpenCL%20Tutorials%20-%201
http://www.fixstars.com/en/opencl/book/OpenCLProgrammingBook/contents/
Хорошие статьи по основам программирования (отдельный интерес вызывает область применения):
http://www.mql5.com/ru/articles/405
http://www.mql5.com/ru/articles/407
Вебинары по OpenCL:
Курс на Udacity по программированию CUDA:
https://www.udacity.com/course/cs344
Выполнение ядра на нескольких GPU:
http://stackoverflow.com/questions/16478968/running-opencl-kernel-on-multiple-gpus
http://www.linkedin.com/groups/Any-new-ideas-on-using-139581.S.97270720
http://www.codeproject.com/Articles/167315/Part-4-Coordinating-Computations-with-OpenCL-Queue
Причем можно пойти по пути упрощения и задействовать один из специальных планировщиков:
http://www.ida.liu.se/~chrke/skepu/
http://aces.snu.ac.kr/Center_for_Manycore_Programming/SnuCL.html
http://runtime.bordeaux.inria.fr/StarPU/
Выполнение нескольких ядер одновременно на одном GPU:
http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#conurrent-kernel-execution
http://stackoverflow.com/questions/12344223/cuda-understanding-concurrent-kernel-execution
http://stackoverflow.com/questions/9311015/cuda-concurrent-kernel-execution-with-multiple-kernels-per-stream
Для ATI карт упоминаний такой возможности я не нашел. В стандарте OpenCL есть флаг CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE но в настоящее время он поддерживается только для CPU.
Серия постов про паттерны параллельного программирования на сайте интела:
http://software.intel.com/en-us/blogs/2009/05/26/parallel-pattern-1-superscalar-sequences-and-task-graphs
http://software.intel.com/en-us/blogs/2009/06/03/parallel-pattern-2-speculative-selection
http://software.intel.com/en-us/blogs/2009/06/10/parallel-patterns-3-map
http://software.intel.com/en-us/blogs/2009/06/24/parallel-pattern-4-gather
http://software.intel.com/en-us/blogs/2009/07/07/parallel-pattern-5-stencils
http://software.intel.com/en-us/blogs/2009/07/14/parallel-pattern-6-partition
http://software.intel.com/en-us/blogs/2009/07/23/parallel-pattern-7-reduce
http://software.intel.com/en-us/blogs/2009/09/15/parallel-pattern-8-scan
http://software.intel.com/en-us/blogs/2009/12/01/parallel-pattern-9-pack
http://software.intel.com/en-us/blogs/2010/06/09/parallel-pattern-10-scatter
CUDA – grid, threads, blocks- раскладываем все по полочкам
http://stackoverflow.com/questions/2392250/understanding-cuda-grid-dimensions-block-dimensions-and-threads-organization-s
http://llpanorama.wordpress.com/2008/06/11/threads-and-blocks-and-grids-oh-my/
доступные в сети ресурсы по CUDA
http://nvlabs.github.io/moderngpu/
https://developer.nvidia.com/content/gpu-gems-part-i-natural-effects
https://developer.nvidia.com/content/gpu-gems-2
https://developer.nvidia.com/content/gpu-gems-3
http://my-it-notes.com/2013/06/bases-of-gpu-optimisation/ – основы оптимизации программ для GPU
Враперы для взаимодействия с ОпенСЛ:
JOCL – Java bindings for OpenCL (JOCL)
PyOpenCL – для python
aparapi – полноценная библиотека для жавы
для хаскела
http://hackage.haskell.org/package/accelerate
http://hackage.haskell.org/package/hopencl
Интересные статью по OpenCL – тут.
доступные материалы курсов по параллельным вычислениям:
http://www.slac.stanford.edu/~rolfa/cudacourse/
http://www.cs.nyu.edu/courses/fall10/G22.2945-001/lectures.html
https://computing.llnl.gov/tutorials/parallel_comp/
http://clcc.sourceforge.net/ – компилятор для OpenCL, удобен для проверки используемых в проекте OpenCL ядер. Поддерживает Windows, Mac. Хотя под Mac – для этих целей можно воспользоваться и “родным”, более продвинутым средством – openclc:
|
1
|
/System/Library/Frameworks/OpenCL.framework/Libraries/openclc -x cl -cl-std=CL1.1 -cl-auto-vectorize-enable -emit-gcl matrix_multiplication.cl |
данная команда не только проверит ваш код на соответствие стандарту OpenCL, но, заодно, создаст и заготовки клиентского кода (в данном случае файлы matrix_multiplication.cl.h/matrix_multiplication.cl.cpp) для вызова ядра из пользовательского приложения.
https://github.com/petRUShka/vim-opencl – плагин для Vim’а с поддержкой проверки синтаксиса OpenCL

 обсудить на форуме
обсудить на форуме |
2258 визитов ↳ 0 ответов | Ваше мнение о материале | Голосовало: 1 |