Статьи
iT заметки
Программирование
Статьи
iT заметки
Программирование
Вычисления на GPU: мифы и реальность
Тот факт, что сегодня вычисления на графическом процессоре (GPU) становятся всё более популярными, не вызывает сомнения. Однако это отнюдь не принижает роли центрального процессора. Более того, если говорить о подавляющем большинстве пользовательских приложений, то на сегодняшний день их производительность целиком и полностью зависит от производительности CPU. То есть подавляющее количество пользовательских приложений не используют вычисления на GPU.
Вообще, вычисления на GPU главным образом выполняются на специализированных HPC-системах для научных расчетов. А вот пользовательские приложения, в которых применяются вычисления на GPU, можно пересчитать по пальцам. При этом следует сразу же оговориться, что термин «вычисления на GPU» в данном случае не вполне корректен и может ввести в заблуждение. Дело в том, что если приложение использует вычисление на GPU, то это вовсе не означает, что центральный процессор бездействует. Вычисление на GPU не предполагает переноса нагрузки с центрального процессора на графический. Как правило, центральный процессор при этом остается загруженным, а использование графического процессора, наряду с центральным, позволяет повысить производительность, то есть сократить время выполнения задачи. Причем сам GPU здесь выступает в роли своеобразного сопроцессора для CPU, но ни в коем случае не заменяет его полностью.
Чтобы разобраться, почему вычисления на GPU не являются эдакой панацеей и почему некорректно утверждать, что их вычислительные возможности превосходят возможности CPU, необходимо уяснить разницу между центральным и графическим процессором.
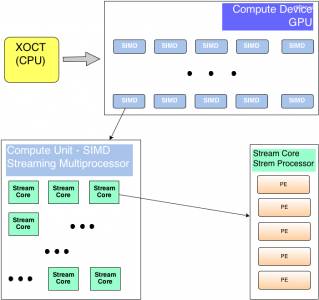
Различия в архитектурах GPU и CPU
Ядра CPU проектируются для выполнения одного потока последовательных инструкций с максимальной производительностью, а GPU — для быстрого исполнения очень большого числа параллельно выполняемых потоков инструкций. В этом и заключается принципиальное отличие графических процессоров от центральных. CPU представляет собой универсальный процессор или процессор общего назначения, оптимизированный для достижения высокой производительности единственного потока команд, обрабатывающего и целые числа, и числа с плавающей точкой. При этом доступ к памяти с данными и инструкциями происходит преимущественно случайным образом.
Для повышения производительности CPU они проектируются так, чтобы выполнять как можно больше инструкций параллельно. Например для этого в ядрах процессора используется блок внеочередного выполнения команд, позволяющий переупорядочивать инструкции не в порядке их поступления, что позволяет поднять уровень параллелизма реализации инструкций на уровне одного потока. Тем не менее это все равно не позволяет осуществить параллельное выполнение большого числа инструкций, да и накладные расходы на распараллеливание инструкций внутри ядра процессора оказываются очень существенными. Именно поэтому процессоры общего назначения имеют не очень большое количество исполнительных блоков.
Графический процессор устроен принципиально иначе. Он изначально проектировался для выполнения огромного количества параллельных потоков команд. Причем эти потоки команд распараллелены изначально, и никаких накладных расходов на распараллеливание инструкций в графическом процессоре просто нет. Графический процессор предназначен для визуализации изображения. Если говорить упрощенно, то на входе он принимает группу полигонов, проводит все необходимые операции и на выходе выдает пикселы. Обработка полигонов и пикселов независима, их можно обрабатывать параллельно, отдельно друг от друга. Поэтому из-за изначально параллельной организации работы в GPU используется большое количество исполнительных блоков, которые легко загрузить, в отличие от последовательного потока инструкций для CPU.
Графические и центральные процессоры различаются и по принципам доступа к памяти. В GPU доступ к памяти легко предсказуем: если из памяти читается тексель текстуры, то через некоторое время придет срок и для соседних текселей. При записи происходит то же самое: если какойто пиксел записывается во фреймбуфер, то через несколько тактов будет записываться пиксел, расположенный рядом с ним. Поэтому GPU, в отличие от CPU, просто не нужна кэшпамять большого размера, а для текстур требуются лишь несколько килобайт. Различен и принцип работы с памятью у GPU и CPU. Так, все современные GPU имеют несколько контроллеров памяти, да и сама графическая память более быстрая, поэтому графические процессоры имеют гораздо большую пропускную способность памяти, по сравнению с универсальными процессорами, что также весьма важно для параллельных расчетов, оперирующих огромными потоками данных.
В универсальных процессорах большую часть площади кристалла занимают различные буферы команд и данных, блоки декодирования, блоки аппаратного предсказания ветвления, блоки переупорядочения команд и кэшпамять первого, второго и третьего уровней. Все эти аппаратные блоки нужны для ускорения исполнения немногочисленных потоков команд за счет их распараллеливания на уровне ядра процессора.
Сами же исполнительные блоки занимают в универсальном процессоре относительно немного места.
В графическом процессоре, наоборот, основную площадь занимают именно многочисленные исполнительные блоки, что позволяет ему одновременно обрабатывать несколько тысяч потоков команд.
Можно сказать, что, в отличие от современных CPU, графические процессоры предназначены для параллельных вычислений с большим количеством арифметических операций.
Использовать вычислительную мощь графических процессоров для неграфических задач возможно, но только в том случае, если решаемая задача допускает возможность распараллеливания алгоритмов на сотни исполнительных блоков, имеющихся в GPU. В частности, выполнение расчетов на GPU показывает отличные результаты в случае, когда одна и та же последовательность математических операций применяется к большому объему данных. При этом лучшие результаты достигаются, если отношение числа арифметических инструкций к числу обращений к памяти достаточно велико. Эта операция предъявляет меньшие требования к управлению исполнением и не нуждается в использовании емкой кэшпамяти.
Можно привести множество примеров научных расчетов, где преимущество GPU над CPU в плане эффективности вычислений неоспоримо. Так, множество научных приложений по молекулярному моделированию, газовой динамике, динамике жидкостей и прочему отлично приспособлено для расчетов на GPU.
Итак, если алгоритм решения задачи может быть распараллелен на тысячи отдельных потоков, то эффективность решения такой задачи с применением GPU может быть выше, чем ее решение средствами только процессора общего назначения. Однако нельзя так просто взять и перенести решение какойто задачи с CPU на GPU, хотя бы просто потому, что CPU и GPU используют разные команды. То есть когда программа пишется под решение на CPU, то применяется набор команд х86 (или набор команд, совместимый с конкретной архитектурой процессора), а вот для графического процессора используются уже совсем другие наборы команд, которые опять-таки учитывают его архитектуру и возможности. При разработке современных 3D-игр применяются API DirectX и OрenGL, позволяющие программистам работать с шейдерами и текстурами. Однако использование API DirectX и OрenGL для неграфических вычислений на графическом процессоре — это не лучший вариант.
NVIDIA CUDA и AMD APP
Именно поэтому, когда стали предприниматься первые попытки реализовать неграфические вычисления на GPU (General Purpose GPU, GPGPU), возник компилятор BrookGPU. До его создания разработчикам приходилось получать доступ к ресурсам видеокарты через графические API OpenGL или Direct3D, что значительно усложняло процесс программирования, так как требовало специфических знаний — приходилось изучать принципы работы с 3D-объектами (шейдерами, текстурами и т.п.). Это явилось причиной весьма ограниченного применения GPGPU в программных продуктах. BrookGPU стал своеобразным «переводчиком». Эти потоковые расширения к языку Си скрывали от программистов трехмерный API и при его использовании надобность в знаниях 3D-программирования практически отпала. Вычислительные мощности видеокарт стали доступны программистам в виде дополнительного сопроцессора для параллельных расчетов. Компилятор BrookGPU обрабатывал файл с кодом Cи и расширениями, выстраивая код, привязанный к библиотеке с поддержкой DirectX или OpenGL.
Во многом благодаря BrookGPU, компании NVIDIA и ATI (ныне AMD) обратили внимание на зарождающуюся технологию вычислений общего назначения на графических процессорах и начали разработку собственных реализаций, обеспечивающих прямой и более прозрачный доступ к вычислительным блокам 3D-ускорителей.
В результате компания NVIDIA разработала программно-аппаратную архитектуру параллельных вычислений CUDA (Compute Unified Device Architecture). Архитектура CUDA позволяет реализовать неграфические вычисления на графических процессорах NVIDIA.
Релиз публичной бета-версии CUDA SDK состоялся в феврале 2007 года. В основе API CUDA лежит упрощенный диалект языка Си. Архитектура CUDA SDK обеспечивает программистам реализацию алгоритмов, выполнимых на графических процессорах NVIDIA, и включение специальных функций в текст программы на Cи. Для успешной трансляции кода на этом языке в состав CUDA SDK входит собственный Сикомпилятор командной строки nvcc компании NVIDIA.
CUDA — это кроссплатформенное программное обеспечение для таких операционных систем, как Linux, Mac OS X и Windows.
Компания AMD (ATI) также разработала свою версию технологии GPGPU, которая ранее называлась AТI Stream, а теперь — AMD Accelerated Parallel Processing (APP). Основу AMD APP составляет открытый индустриальный стандарт OpenCL (Open Computing Language). Стандарт OpenCL обеспечивает параллелизм на уровне инструкций и на уровне данных и является реализацией техники GPGPU. Это полностью открытый стандарт, его использование не облагается лицензионными отчислениями. Отметим, что AMD APP и NVIDIA CUDA несовместимы друг с другом, тем не менее, последняя версия NVIDIA CUDA поддерживает и OpenCL.
Тестирование GPGPU в видеоконвертерах
Итак, мы выяснили, что для реализации GPGPU на графических процессорах NVIDIA предназначена технология CUDA, а на графических процессорах AMD — API APP. Как уже отмечалось, использование неграфических вычислений на GPU целесообразно только в том случае, если решаемая задача может быть распараллелена на множество потоков. Однако большинство пользовательских приложений не удовлетворяют этому критерию. Впрочем, есть и некоторые исключения. К примеру, большинство современных видеоконвертеров поддерживают возможность использования вычислений на графических процессорах NVIDIA и AMD.
Для того чтобы выяснить, насколько эффективно используются вычисления на GPU в пользовательских видеоконвертерах, мы отобрали три популярных решения: Xilisoft Video Converter Ultimate 7.7.2, Wondershare Video Converter Ultimate 6.0.3.2 и Movavi Video Converter 10.2.1. Эти конвертеры поддерживают возможность использования графических процессоров NVIDIA и AMD, причем в настройках видеоконвертеров можно отключить эту возможность, что позволяет оценить эффективность применения GPU.
Для видеоконвертирования мы применяли три различных видеоролика.
Первый видеоролик имел длительность 3 мин 35 с и размер 1,05 Гбайт. Он был записан в формате хранения данных (контейнер) mkv и имел следующие характеристики:
- видео:
- формат — MPEG4 Video (H264),
- разрешение — 1920*um*1080,
- режим битрейта — Variable,
- средний видеобитрейт — 42,1 Мбит/с,
- максимальный видеобитрейт — 59,1 Мбит/с,
- частота кадров — 25 fps;
- аудио:
- формат — MPEG-1 Audio,
- аудиобитрейт — 128 Кбит/с,
- количество каналов — 2,
- частота семплирования — 44,1 кГц.
Второй видеоролик имел длительность 4 мин 25 с и размер 1,98 Гбайт. Он был записан в формате хранения данных (контейнер) MPG и имел следующие характеристики:
- видео:
- формат — MPEG-PS (MPEG2 Video),
- разрешение — 1920*um*1080,
- режим битрейта — Variable.
- средний видеобитрейт — 62,5 Мбит/с,
- максимальный видеобитрейт — 100 Мбит/с,
- частота кадров — 25 fps;
- аудио:
- формат — MPEG-1 Audio,
- аудиобитрейт — 384 Кбит/с,
- количество каналов — 2,
- частота семплирования — 48 кГц.
Третий видеоролик имел длительность 3 мин 47 с и размер 197 Мбайт. Он был записан в формате хранения данных (контейнер) MOV и имел следующие характеристики:
- видео:
- формат — MPEG4 Video (H264),
- разрешение — 1920*um*1080,
- режим битрейта — Variable,
- видеобитрейт — 7024 Кбит/с,
- частота кадров — 25 fps;
- аудио:
- формат — AAC,
- аудиобитрейт — 256 Кбит/с,
- количество каналов — 2,
- частота семплирования — 48 кГц.
Все три тестовых видеоролика конвертировались с использованием видеоконвертеров в формат хранения данных MP4 (кодек H.264) для просмотра на планшете iPad 2. Разрешение выходного видеофайла составляло 1280*um*720.
Отметим, что мы не стали использовать абсолютно одинаковые настройки конвертирования во всех трех конвертерах. Именно поэтому по времени конвертирования некорректно сравнивать эффективность самих видеоконвертеров. Так, в видеоконвертере Xilisoft Video Converter Ultimate 7.7.2 для конвертирования применялся пресет iPad 2 — H.264 HD Video. В этом пресете используются следующие настройки кодирования:
- кодек — MPEG4 (H.264);
- разрешение — 1280*um*720;
- частота кадров — 29,97 fps;
- видеобитрейт — 5210 Кбит/с;
- аудиокодек — AAC;
- аудиобитрейт — 128 Кбит/с;
- количество каналов — 2;
- частота семплирования — 48 кГц.
В видеоконвертере Wondershare Video Converter Ultimate 6.0.3.2 использовался пресет iPad 2 cо следующими дополнительными настройками:
- кодек — MPEG4 (H.264);
- разрешение — 1280*um*720;
- частота кадров — 30 fps;
- видеобитрейт — 5000 Кбит/с;
- аудиокодек — AAC;
- аудиобитрейт — 128 Кбит/с;
- количество каналов — 2;
- частота семплирования — 48 кГц.
В конвертере Movavi Video Converter 10.2.1 применялся пресет iPad (1280*um*720, H.264) (*.mp4) со следующими дополнительными настройками:
- видеоформат — H.264;
- разрешение — 1280*um*720;
- частота кадров — 30 fps;
- видеобитрейт — 2500 Кбит/с;
- аудиокодек — AAC;
- аудиобитрейт — 128 Кбит/с;
- количество каналов — 2;
- частота семплирования — 44,1 кГц.
Конвертирование каждого исходного видеоролика проводилось по пять раз на каждом из видеоконвертеров, причем с использованием как графического процессора, так и только CPU. После каждого конвертирования компьютер перезагружался.
В итоге, каждый видеоролик конвертировался десять раз в каждом видеоконвертере. Для автоматизации этой рутинной работы была написана специальная утилита с графическим интерфейсом, позволяющая полностью автоматизировать процесс тестирования.
Конфигурация стенда для тестирования
Стенд для тестирования имел следующую конфигурацию:
- процессор — Intel Core i7-3770K;
- материнская плата — Gigabyte GA-Z77X-UD5H;
- чипсет системной платы — Intel Z77 Express;
- память — DDR3-1600;
- объем памяти — 8 Гбайт (два модуля GEIL по 4 Гбайт);
- режим работы памяти — двухканальный;
- видеокарта — NVIDIA GeForce GTX 660Ti (видеодрайвер 314.07);
- накопитель — Intel SSD 520 (240 Гбайт).
На стенде устанавливалась операционная система Windows 7 Ultimate (64-bit).
Первоначально мы провели тестирование в штатном режиме работы процессора и всех остальных компонентов системы. При этом процессор Intel Core i7-3770K работал на штатной частоте 3,5 ГГц c активированным режимом Turbo Boost (максимальная частота процессора в режиме Turbo Boost составляет 3,9 ГГц).
Затем мы повторили процесс тестирования, но при разгоне процессора до фиксированной частоты 4,5 ГГц (без использования режима Turbo Boost). Это позволило выявить зависимость скорости конвертирования от частоты процессора (CPU).
На следующем этапе тестирования мы вернулись к штатным настройкам процессора и повторили тестирование уже с другими видеокартами:
- NVIDIA GeForce GTX 280 (драйвер 314.07);
- NVIDIA GeForce GTX 460 (драйвер 314.07);
- AMD Radeon HD6850 (драйвер 13.1).
Таким образом, видеоконвертирование проводилось на четырех видеокартах различной архитектуры.
Старшая видеокарта NVIDIA GeForce 660Ti основана на одноименном графическом процессоре с кодовым обозначением GK104 (архитектура Kepler), производимом по 28-нм техпроцессу. Этот графический процессор содержит 3,54 млрд транзисторов, а площадь кристалла составляет 294 мм2.
Напомним, что графический процессор GK104 включает четыре кластера графической обработки (Graphics Processing Clusters, GPC). Кластеры GPC являются независимыми устройствами в составе процессора и способны работать как отдельные устройства, поскольку обладают всеми необходимыми ресурсами: растеризаторами, геометрическими движками и текстурными модулями.
Каждый такой кластер имеет два потоковых мультипроцессора SMX (Streaming Multiprocessor), но в процессоре GK104 в одном из кластеров один мультипроцессор заблокирован, поэтому всего имеется семь мультипроцессоров SMX.
Каждый потоковый мультипроцессор SMX содержит 192 потоковых вычислительных ядра (ядра CUDA), поэтому в совокупности процессор GK104 насчитывает 1344 вычислительных ядра CUDA. Кроме того, каждый SMX-мультипроцессор содержит 16 текстурных модулей (TMU), 32 блока специальных функций (Special Function Units, SFU), 32 блока загрузки и хранения (Load-Store Unit, LSU), движок PolyMorph и многое другое.
Видеокарта GeForce GTX 460 основана на графическом процессоре с кодовым обозначением GF104 на базе архитектуры Fermi. Этот процессор производится по 40-нм техпроцессу и содержит порядка 1,95 млрд транзисторов.
Графический процессор GF104 включает два кластера графической обработки GPC. Каждый из них имеет четыре потоковых мультипроцессора SM, но в процессоре GF104 в одном из кластеров один мультипроцессор заблокирован, поэтому существует всего семь мультипроцессоров SM.
Каждый потоковый мультипроцессор SM содержит 48 потоковых вычислительных ядра (ядра CUDA), поэтому в совокупности процессор GK104 насчитывает 336 вычислительных ядра CUDA. Кроме того, каждый SM-мультипроцессор содержит восемь текстурных модулей (TMU), восемь блоков специальных функций (Special Function Units, SFU), 16 блоков загрузки и хранения (Load-Store Unit, LSU), движок PolyMorph и многое другое.
Графический процессор GeForce GTX 280 относится ко второму поколению унифицированной архитектуры графических процессоров NVIDIA и по своей архитектуре сильно отличается от архитектуры Fermi и Kepler.
Графический процессор GeForce GTX 280 состоит из кластеров обработки текстур (Texture Processing Clusters, TPC), которые, хоть и похожи, но в то же время сильно отличаются от кластеров графической обработки GPC в архитектурах Fermi и Kepler. Всего таких кластеров в процессоре GeForce GTX 280 насчитывается десять. Каждый TPC-кластер включает три потоковых мультипроцессора SM и восемь блоков текстурной выборки и фильтрации (TMU). Каждый мультипроцессор состоит из восьми потоковых процессоров (SP). Мультипроцессоры также содержат блоки выборки и фильтрации текстурных данных, используемых как в графических, так и в некоторых расчетных задачах.
Таким образом, в одном TPC-кластере — 24 потоковых процессора, а в графическом процессоре GeForce GTX 280 их уже 240.
Сводные характеристики используемых в тестировании видеокарт на графических процессорах NVIDIA представлены в таблице.
В приведенной таблице нет видеокарты AMD Radeon HD6850, что вполне естественно, поскольку по техническим характеристикам ее трудно сравнивать с видеокартами NVIDIA. А потому рассмотрим ее отдельно.
Графический процессор AMD Radeon HD6850, имеющий кодовое наименование Barts, изготовляется по 40-нм техпроцессу и содержит 1,7 млрд транзисторов.
Архитектура процессора AMD Radeon HD6850 представляет собой унифицированную архитектуру с массивом общих процессоров для потоковой обработки многочисленных видов данных.
Процессор AMD Radeon HD6850 состоит из 12 SIMD-ядер, каждое из которых содержит по 16 блоков суперскалярных потоковых процессоров и четыре текстурных блока. Каждый суперскалярный потоковый процессор содержит пять универсальных потоковых процессоров. Таким образом, всего в графическом процессоре AMD Radeon HD6850 насчитывается 12*um*16*um*5=960 универсальных потоковых процессоров.
Частота графического процессора видеокарты AMD Radeon HD6850 составляет 775 МГц, а эффективная частота памяти GDDR5 — 4000 МГц. При этом объем памяти составляет 1024 Мбайт.
Результаты тестирования
Итак, давайте обратимся к результатам тестирования. Начнем с первого теста, когда используется видеокарта NVIDIA GeForce GTX 660Ti и штатный режим работы процессора Intel Core i7-3770K.
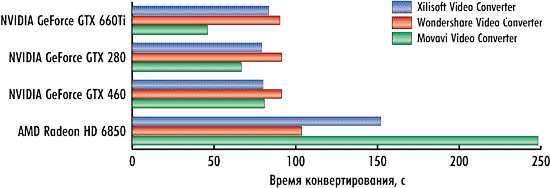
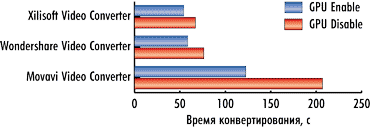
На рис. 1-3 показаны результаты конвертирования трех тестовых видеороликов тремя конвертерами в режимах с применением графического процессора и без.
Как видно по результатам тестирования, эффект от использования графического процессора налицо. Для видеоконвертера Xilisoft Video Converter Ultimate 7.7.2 в случае применения графического процессора время конвертирования сокращается на 14, 9 и 19% для первого, второго и третьего видеоролика соответственно.
Для видеоконвертера Wondershare Video Converter Ultimate 6.0.32 использование графического процессора позволяет сократить время конвертирования на 10, 13 и 23% для первого, второго и третьего видеоролика соответственно.
Но более всех от применения графического процессора выигрывает конвертер Movavi Video Converter 10.2.1. Для первого, второго и третьего видеоролика сокращение времени конвертирования составляет 64, 81 и 41% соответственно.
Понятно, что выигрыш от использования графического процессора зависит и от исходного видеоролика, и от настроек видеоконвертирования, что, собственно, и демонстрируют полученные нами результаты.
Теперь посмотрим, каков будет выигрыш по времени конвертирования при разгоне процессора Intel Core i7-3770K до частоты 4,5 ГГц. Если считать, что в штатном режиме все ядра процессора при конвертировании загружены и в режиме Turbo Boost работают на частоте 3,7 ГГц, то увеличение частоты до 4,5 ГГц соответствует разгону по частоте на 22%.
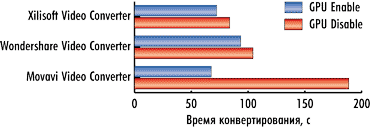
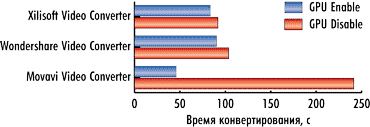
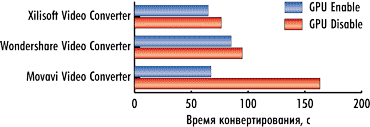
На рис. 4-6 показаны результаты конвертирования трех тестовых видеороликов при разгоне процессора в режимах с использованием графического процессора и без. В данном случае применение графического процессора позволяет получить выигрыш по времени конвертирования.
Для видеоконвертера Xilisoft Video Converter Ultimate 7.7.2 в случае применения графического процессора время конвертирования сокращается на 15, 9 и 20% для первого, второго и третьего видеоролика соответственно.
Для видеоконвертера Wondershare Video Converter Ultimate 6.0.32 использование графического процессора позволяет сократить время конвертирования на 10, 10 и 20% для первого, второго и третьего видеоролика соответственно.
Для конвертера Movavi Video Converter 10.2.1 применение графического процессора позволяет сократить время конвертирования на 59, 81 и 40% соответственно.
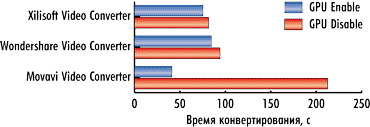
Естественно, интересно посмотреть, как разгон процессора позволяет уменьшить время конвертирования при использовании графического процессора и без него.
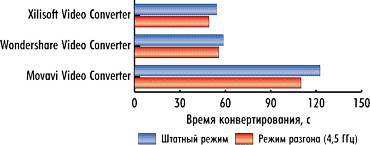
На рис. 7-9 представлены результаты сравнения времени конвертирования видеороликов без использования графического процессора в штатном режиме работы процессора и в режиме разгона. Поскольку в данном случае конвертирование проводится только средствами CPU без вычислений на GPU, очевидно, что увеличение тактовой частоты работы процессора приводит к сокращению времени конвертирования (увеличению скорости конвертирования). Столь же очевидно, что сокращение скорости конвертирования должно быть примерно одинаково для всех тестовых видеороликов. Так, для видеоконвертера Xilisoft Video Converter Ultimate 7.7.2 при разгоне процессора время конвертирования сокращается на 9, 11 и 9% для первого, второго и третьего видеоролика соответственно. Для видеоконвертера Wondershare Video Converter Ultimate 6.0.32 время конвертирования сокращается на 9, 9 и 10% для первого, второго и третьего видеоролика соответственно. Ну а для видеоконвертера Movavi Video Converter 10.2.1 время конвертирования сокращается на 13, 12 и 12% соответственно.
Таким образом, при разгоне процессора по частоте на 20% время конвертирования сокращается примерно на 10%.
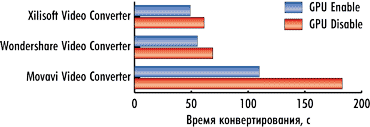
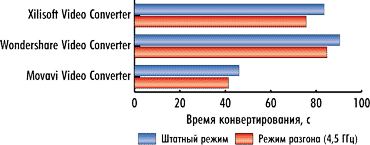
Сравним время конвертирования видеороликов с использованием графического процессора в штатном режиме работы процессора и в режиме разгона (рис. 10-12).
Для видеоконвертера Xilisoft Video Converter Ultimate 7.7.2 при разгоне процессора время конвертирования сокращается на 10, 10 и 9% для первого, второго и третьего видеоролика соответственно. Для видеоконвертера Wondershare Video Converter Ultimate 6.0.32 время конвертирования сокращается на 9, 6 и 5% для первого, второго и третьего видеоролика соответственно. Ну а для видеоконвертера Movavi Video Converter 10.2.1 время конвертирования сокращается на 0,2, 10 и 10% соответственно.
Как видим, для конвертеров Xilisoft Video Converter Ultimate 7.7.2 и Wondershare Video Converter Ultimate 6.0.32 сокращение времени конвертирования при разгоне процессора примерно одинаково как при использовании графического процессора, так и без его применения, что логично, поскольку эти конвертеры не очень эффективно используют вычисления на GPU. А вот для конвертера Movavi Video Converter 10.2.1, который эффективно использует вычисления на GPU, разгон процессора в режиме использования вычислений на GPU мало сказывается на сокращении времени конвертирования, что также понятно, поскольку в данном случае основная нагрузка ложится на графический процессор.
Теперь посмотрим результаты тестирования с различными видеокартами.
Казалось бы, чем мощнее видеокарта и чем больше в графическом процессоре ядер CUDA (или универсальных потоковых процессоров для видеокарт AMD), тем эффективнее должно быть видеоконвертирование в случае применения графического процессора. Но на практике получается не совсем так.
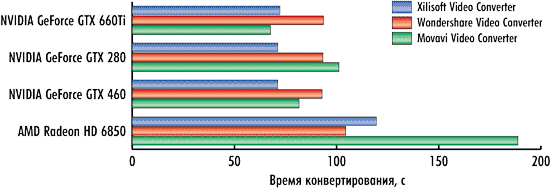
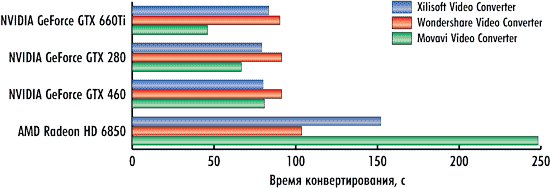
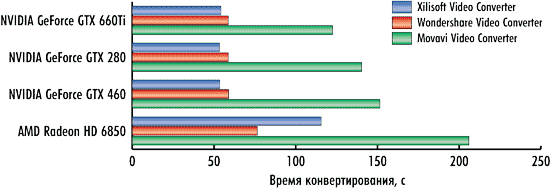
Что касается видеокарт на графических процессорах NVIDIA, то ситуация следующая. При использовании конвертеров Xilisoft Video Converter Ultimate 7.7.2 и Wondershare Video Converter Ultimate 6.0.32 время конвертирования практически никак не зависит от типа используемой видеокарты. То есть для видеокарт NVIDIA GeForce GTX 660Ti, NVIDIA GeForce GTX 460 и NVIDIA GeForce GTX 280 в режиме использования вычислений на GPU время конвертирования получается одно и то же (рис. 13-15).
 |
 |
|
Рис. 1. Результаты конвертирования первого
тестового видеоролика в штатном режиме работы процессора |
Рис. 2. Результаты конвертирования второго
тестового видеоролика в штатном режиме работы процессора |
 |
 |
|
Рис. 3. Результаты конвертирования третьего тестового видеоролика в штатном режиме работы
процессора |
Рис. 4. Результаты конвертирования первого
тестового видеоролика в режиме разгона процессора |
 |
 |
|
Рис. 5. Результаты конвертирования второго
тестового видеоролика в режиме разгона процессора |
Рис. 6. Результаты конвертирования третьего
тестового видеоролика в режиме разгона процессора |
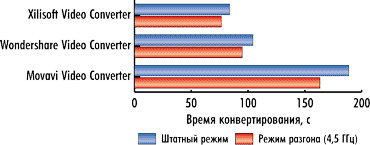 |
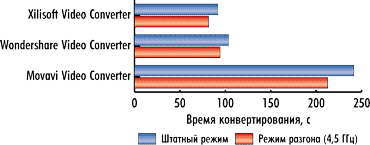 |
|
Рис. 7. Результаты сравнения времени
конвертирования первого видеоролика без использования графического процессора в штатном режиме работы процессора и в режиме разгона |
Рис. 8. Результаты сравнения времени
конвертирования второго видеоролика без использования графического процессора в штатном режиме работы процессора и в режиме разгона |
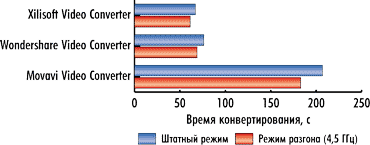 |
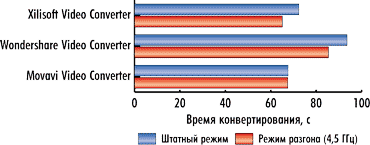 |
|
Рис. 9. Результаты сравнения времени конвертирования
третьего видеоролика без использования графического процессора в штатном режиме работы процессора и в режиме разгона |
Рис. 10. Результаты сравнения времени
конвертирования первого видеоролика с использованием графического процессора в штатном режиме и в режиме разгона |
 |
 |
|
Рис. 11. Результаты сравнения времени
конвертирования второго видеоролика с использованием графического процессора в штатном режиме и в режиме разгона |
Рис. 12. Результаты сравнения времени
конвертирования третьего видеоролика с использованием графического процессора в штатном режиме работы процессора и в режиме разгона |
 |
|
|
Рис. 13. Результаты сравнения времени конвертирования первого видеоролика на различных
видеокартах в режиме использования графического процессора |
|
 |
|
|
Рис. 14. Результаты сравнения времени конвертирования второго видеоролика
на различных видеокартах в режиме использования графического процессора |
|
 |
|
|
Рис. 15. Результаты сравнения времени конвертирования третьего видеоролика
на различных видеокартах в режиме использования графического процессора |
|
Объяснить это можно лишь тем, что алгоритм вычислений на графическом процессоре, реализованный в конвертерах Xilisoft Video Converter Ultimate 7.7.2 и Wondershare Video Converter Ultimate 6.0.32, просто неэффективен и не позволяет активно задействовать все графические ядра. Кстати, именно этим объясняется и тот факт, что для этих конвертеров разница по времени конвертирования в режимах использования GPU и без использования невелика.
В конвертере Movavi Video Converter 10.2.1 ситуация несколько иная. Как мы помним, этот конвертер способен очень эффективно использовать вычисления на GPU, а поэтому в режиме использования GPU время конвертирования зависит от типа используемой видеокарты.
А вот с видеокартой AMD Radeon HD 6850 всё как обычно. То ли драйвер видеокарты «кривой», то ли алгоритмы, реализованные в конвертерах, нуждаются в серьезной доработке, но в случае применения вычислений на GPU результаты либо не улучшаются, либо ухудшаются.
Если говорить более конкретно, то ситуация следующая. Для конвертера Xilisoft Video Converter Ultimate 7.7.2 при использовании графического процессора для конвертирования первого тестового видеоролика время конвертирования увеличивается на 43%, при конвертировании второго ролика — на 66%.
Причем, конвертер Xilisoft Video Converter Ultimate 7.7.2 характеризуется еще и нестабильностью результатов. Разброс по времени конвертирования может достигать 40%! Именно поэтому мы повторяли все тесты по десять раз и рассчитывали средний результат.
А вот для конвертеров Wondershare Video Converter Ultimate 6.0.32 и Movavi Video Converter 10.2.1 при использовании графического процессора для конвертирования всех трех видеороликов время конвертирования не изменяется вообще! Вероятно, что конвертеры Wondershare Video Converter Ultimate 6.0.32 и Movavi Video Converter 10.2.1 либо не используют технологию AMD APP при конвертировании, либо видеодрайвер AMD попросту «кривой», в результате чего технология AMD APP не работает.
Выводы
На основании проведенного тестирования можно сделать следующие важные выводы. В современных видеоконвертерах действительно может применяться технология вычислений на GPU, что позволяет повысить скорость конвертирования. Однако это вовсе не означает, что все вычисления целиком переносятся на GPU и CPU остается незадействованным. Как показывает тестирование, при использовании технологии GPGPU центральный процессор остается загруженным, а значит, применение мощных, многоядерных центральных процессоров в системах, используемых для конвертирования видео, остается актуальным. Исключением из этого правила является технология AMD APP на графических процессорах AMD. Например, при использовании конвертера Xilisoft Video Converter Ultimate 7.7.2 с активированной технологией AMD APP нагрузка на CPU действительно снижается, но это приводит к тому, что время конвертирования не сокращается, а, наоборот, увеличивается.
Вообще, если говорить о конвертировании видео с дополнительным использованием графического процессора, то для решения этой задачи целесообразно применять видеокарты с графическими процессорами NVIDIA. Как показывает практика, только в этом случае можно добиться увеличения скорости конвертирования. Причем нужно помнить, что реальный прирост в скорости конвертирования зависит от очень многих факторов. Это входной и выходной форматы видео, и, конечно же, сам видеоконвертер. Конвертеры Xilisoft Video Converter Ultimate 7.7.2 и Wondershare Video Converter Ultimate 6.0.32 для этой задачи подходят плохо, а вот конвертер и Movavi Video Converter 10.2.1 способен очень эффективно использовать возможности NVIDIA GPU.
Что же касается видеокарт на графических процессорах AMD, то для задач видеоконвертирования их не стоит применять вообще. В лучшем случае никакого прироста в скорости конвертирования это не даст, а в худшем — можно получить ее снижение.

 обсудить на форуме
обсудить на форуме |
1899 визитов ↳ 0 ответов | Ваше мнение о материале | Голосовало: 3 |